K means (Non Hierarchical)
from sklearn.cluster import KMeans
It is based on division of objects into non overlapping subsets. Main objective is to form clusters that are homogeneous in nature and heterogeneous to each other.
❕ Only for continuous variables.
Advantages
- Faster, more reliable, works with large data.
- Computationally lighter than other methods
Disadvantages
- Can only identify clusters circular / spherical in nature. (check crescent dataset)
- Distance based
Process
- Identify value of ‘k’
- Assign random k observations as seeds
- Assign each record to one of the k seeds based on proximity
- Form clusters
- Calculate centroids of clusters
- Assign centroids as new seed
- Form new clusters
- Recalculate clusters
- Continue process until stable clusters are formed (boundary ceases to change)
Elbow Criterion (Scree Plot):
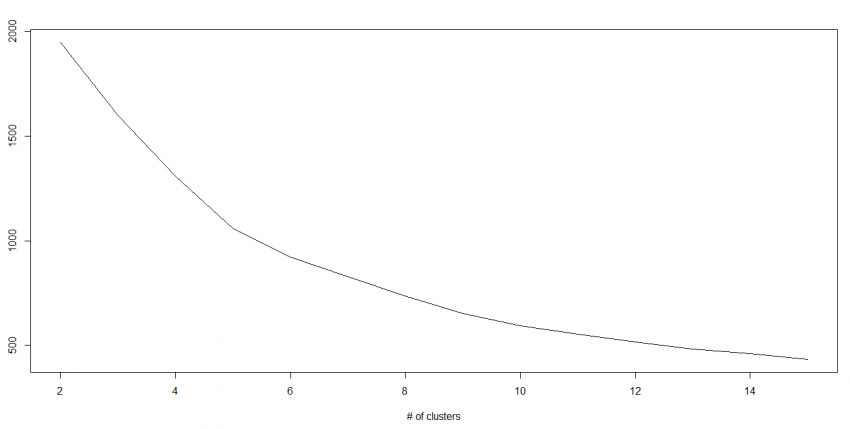
K means clustering doesn’t provide an estimate of the number of clusters required. Hence elbow criterion is used to determine optimal number of clusters.
The method states that you should choose a number of clusters so that adding another cluster does not add any sufficient information. It is plotted by ratio of within cluster variance to between cluster variance against number of clusters. The objective is to minimize the within and maximize the between distances.
Validation:
- Silhouette Index
- Davies Bouldin Score
- Calinski Harabasz Score
- Pseudo F
Parameter Tuning
km = Kmeans(n_clusters=2, max_iter=100)
km.fit(X_std)