Logistic Regression
from sklearn.linear_model import LogisticRegression
Although Logistic Regression is termed a Regression, it is in fact a method of Classification. The underlying methodology utilized concepts to linear regression and hence the name sayed.
Method = Maximum Likelihood Estimation / Chi-square
Logistic Regression is used to model the probability of an outcome. It is based on concept of Generalized Linear Model (GLM).
Dependent Variable Y = Binary (eg 0 or 1)
Independent Variable X = Continuous or Categorical
Since the dependent variable is binary, errors will be non-normally distributed. Also, Errors are heteroskedastic
Types
- Binary / Dichotomous - Dependent Variable is binary in nature (eg. 0/1)
- Ordered - Dependent Variable has ordered levels eg High, Medium, & Low
- Multinomial - Dependent Variable is nominal with more than two levels
Assumptions
- Binary logistic regression requires the dependent variable to be binary coded
- Model should have little or no multicollinearity
- Model should be fitted correctly: Neither overfitting or underfitting should occur
- The error terms should be independent ie the data should not be before-after samples
- Requires comparatively larger data sample (min 30 observations)
- There should be no outliers. Assessed by converting predictors to standardized or z scores and remove values below or greater than -3.29 or 3.29
Technique
It is similar to linear regression, except the Y variable is not regressed directly, instead the log odds ratio of Y is regressed.
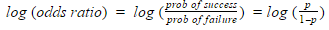
Logit is a log of odds and odds are a function of P.

| Step | Type | Range |
|---|---|---|
| a | Linear regression | -∞ to +∞ |
| b | Probability values | 0 to 1 |
| c | Odds ratio | 0 to ∞ |
| d | Log odds ratio | -∞ to +∞ |
(natural) Log of odds is taken for better expressing the results :
eg: odds of 90% and 10% expressed as :: (0.9/0.1) = 9 and conversely, (0.1/0.9) = 0.11
However ln(0.9/0.1) = 2.217 and conversely, ln(0.1/0.9) = -2.217 relates in a much better way.
Interpretation: Logistic regression coefficients give the change in the log odds of the outcome for a one unit increase in the predictor variable
Hyperparameters
Output
- Null Deviance : Indicates the response predicted by a model with nothing but an intercept.Lower the value, better the model. The difference between null and residual deviance should also be high
- Residual Deviance : Residual deviance indicates the response predicted by a model on adding independent variables. Lower the value, better the model
- Fisher’s score : how far the model had to reiterate to get to the results, similar to AIC value.
Validation
- Same significant variables should come in both the training and validation sample.
- The behavior of variables should be same in both the samples (same sign of coefficients)
- Beta coefficients should be close in training and validation samples
- KS statistics should be in top 3 deciles
- KS statistics should be between 40 and 70
- Rank Ordering - There should not be any break in rank ordering.
- Lift Curve - The larger the cumulative lift value the better the accuracy
- Goodness of Fit Tests - Model should fit the data well. Check Hosmer and Lemeshow Test and Deviance and Residual Test.
Loss Function
- A loss function is a measure of fit between a mathematical model of data and the actual data.
- Parameters of the model are chosen that minimize the badness of fit or maximize the goodness of fit of the model to the data
- With least squares, minimize SSres, the sum of squares residual and maximize the SSreg the sum of squares due to regression.
- With the logistic curve there is no mathematical solution that will produce the least squares estimates of the parameters. It’s more of an optimization problem
- For many of these models, the loss function chosen is called maximum likelihood
A likelihood is a conditional probability (eg P(Y|X), the probability of Y given X).